
How Big Data is Empowering AI and Machine Learning

Together, Big Data and Artificial Intelligence (AI) form a virtuous cycle that is reshaping industries, redefining business models, and driving innovation across every digital sector. Each reinforces the other: Big Data provides the scale and diversity of information needed for AI to learn effectively, while AI converts data into intelligence that enhances decision-making, efficiency, and foresight.
In the digital economy, the ability to harness data efficiently defines competitive advantage. Big Data can store and process petabytes of structured and unstructured information. But when paired with AI and Machine Learning (ML), that data becomes a strategic asset capable of predicting customer behavior, automating complex workflows, and enabling personalized user experiences.
According to the NewVantage Partners’ Big Data Executive Survey, 88.5% of executives agreed that AI and ML would disrupt their industries within a decade. 37% had already invested over $1 million in Big Data initiatives, while 6.5% exceeded $1 billion — an early sign of a global transformation that continues today.
In 2025, IDC predicts that the global data sphere will reach over 180 zettabytes, with AI consuming a growing share of that data for model training and inference. The convergence of Big Data and AI is no longer optional; it is the foundation of digital transformation.
The Forces Driving Big Data and AI Convergence

The partnership between AI and Big Data has been accelerated by several interdependent forces — technological advancements, cost efficiencies, and the rising complexity of business decisions.
1. Explosive Growth of Global Data
The world is now producing data at an unprecedented pace — generated from social media, connected vehicles, IoT devices, industrial sensors, and mobile applications. Every click, swipe, and interaction contributes to this digital footprint.
- Volume: Enterprises manage terabytes of transaction logs, clickstream data, video feeds, and text files daily.
- Velocity: Streaming data from devices, sensors, and applications needs to be processed in milliseconds to be useful.
- Variety: Data comes in all forms — images, audio, logs, structured relational data, and unstructured documents.
Traditional data warehouses weren’t designed for this complexity. Big Data platforms such as Apache Hadoop, Spark, and Flink emerged to process these high-volume, high-velocity data streams efficiently — paving the way for AI systems that thrive on diversity and scale.
2. Advances in Computational Power
AI’s renaissance owes much to computing evolution. High-performance GPUs, TPUs, and distributed compute clusters now make it possible to train billion-parameter models on enormous datasets.
Cloud platforms such as AWS EC2, Google Cloud Vertex AI, and Azure ML have democratized this power, letting enterprises rent computing resources on demand.
Additionally, frameworks like PyTorch, TensorFlow, and Hugging Face Transformers have lowered the technical barrier for building production-grade AI systems. This marriage of computational scalability and algorithmic sophistication fuels the next generation of AI models — from generative transformers to predictive maintenance engines.
3. Affordable and Elastic Data Storage
A decade ago, storage was the biggest bottleneck. Today, the cost per gigabyte of cloud storage has fallen by over 90%. This has enabled organizations to store massive historical datasets that would previously be discarded.
Platforms like Google BigQuery, Amazon S3, Databricks Delta Lake, and Snowflake not only store data cheaply but also make it instantly accessible for analytics and ML workloads. These solutions bring elasticity — expanding storage or compute power dynamically based on need — making it feasible for AI to operate on live, constantly growing datasets.
4. Algorithmic and Analytical Innovation
Modern AI algorithms — from transformers, reinforcement learning, and self-supervised models — require massive datasets to perform optimally. But they also create value from data that was once too noisy or unstructured to use.
Big Data provides the infrastructure and preprocessing capabilities — cleaning, labeling, and transforming raw data into machine-readable formats. In return, AI brings deeper pattern recognition and insight extraction to that data. Together, they enable applications like fraud detection, medical diagnostics, predictive logistics, and conversational AI at industrial scale.
Delivering the Right Data at the Right Time
AI systems are only as good as the data they consume. Even the most advanced model fails when fed with incomplete, outdated, or biased data. Big Data ensures that the right information reaches AI and Machine Learning systems at the exact moment it’s needed — clean, relevant, and context-rich.
Modern enterprises therefore invest heavily in data pipelines, governance frameworks, and real-time delivery architectures to guarantee that data not only exists but also arrives in a usable form. This section explores how organizations make that happen.
1. Building Unified Data Pipelines
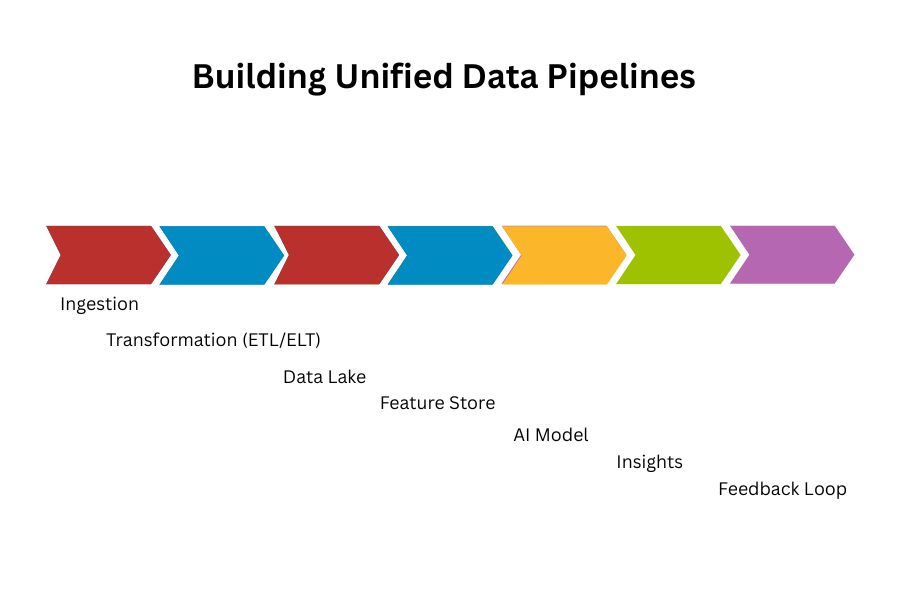
At the heart of data timeliness lies the pipeline — a coordinated system that moves data from diverse sources to analytical and AI systems.
Key components of modern pipelines:
- Ingestion Layer – Collects raw data from APIs, IoT sensors, databases, applications, and logs. Tools: Apache Kafka, AWS Kinesis, Google Pub/Sub.
- Transformation Layer (ETL / ELT) – Cleanses, enriches, and standardizes data. Technologies like dbt, Spark, Flink, or Airflow perform schema alignment and type casting.
- Storage Layer – Houses the processed data in scalable environments like Snowflake, BigQuery, or Delta Lake.
- Serving Layer – Exposes curated datasets to AI/ML frameworks via APIs, vector databases, or feature stores.
In essence, Big Data turns the messy world of unstructured, multi-source information into a well-orchestrated supply chain feeding the AI “brain.”
Example:
A global airline aggregates data from ticket sales, flight telemetry, maintenance logs, and customer feedback into a unified lake. Once standardized, this data is streamed into ML systems predicting flight delays or optimizing crew assignments — all in real time.
2. Data Quality and Governance
The “right” data isn’t just recent — it’s accurate, consistent, and trustworthy. Big Data systems enforce this through data governance and observability frameworks that ensure reliability from source to model.
Core practices include:
- Validation Rules: Checking formats, ranges, and referential integrity at ingestion.
- Deduplication and Error Correction: Removing anomalies introduced by sensors or manual input.
- Lineage Tracking: Recording where every field came from, who modified it, and when.
- Access Control & Compliance: Using role-based permissions to meet GDPR, HIPAA, or CCPA obligations.
Emerging platforms such as Monte Carlo, Collibra, and DataHub give enterprises visibility into their data health.
This governance layer prevents “data drift” — the gradual degradation of AI model performance due to unseen data inconsistencies.
Outcome:
AI models trained on governed data demonstrate higher precision, lower bias, and better reproducibility — crucial in regulated sectors like finance or healthcare.
3. Feature Engineering and Data Preparation
Feeding data into AI systems isn’t a direct process. Data scientists must transform raw information into features — quantifiable attributes that algorithms can learn from.
Big Data enables:
- Automatic feature extraction from text, image, and sensor data at scale.
- Creation of feature stores (like Feast or Tecton) where reusable, versioned features are stored for multiple models.
- Continuous feature refresh pipelines that update model inputs as soon as new data arrives.
For example, an eCommerce company might engineer features such as:
- average time between purchases
- discount responsiveness
- session length per device type
These features, refreshed hourly, allow real-time models to recommend products or adjust pricing dynamically.
Why it matters:
Feature engineering is where the “intelligence” of AI truly begins. Big Data pipelines automate and accelerate this process, ensuring fresh, contextually meaningful signals power each prediction.
4. Real-Time and Streaming Data Delivery
Batch-processed data once dominated analytics. But AI increasingly depends on real-time insight — fraud detection, predictive maintenance, or personalization cannot wait hours for updates.
Big Data technologies like Apache Flink, Spark Streaming, and Kafka Streams now allow millisecond-level data flow from event to model.
Example:
- A payment processor uses Kafka to detect anomalies in transaction patterns instantly.
- When a card purchase deviates from a user’s normal behavior profile, the AI model flags it in real time — preventing fraud before authorization.
This “streaming intelligence” is what enables reactive and adaptive AI, where insights are generated while events are happening, not after.
5. Data Observability and Feedback Loops
Delivering data once isn’t enough — systems must observe and measure the reliability of data in motion.
Data observability ensures every stage of the pipeline functions as intended, similar to how application monitoring ensures uptime.
Common metrics include:
- Freshness: How current is the data the AI model sees?
- Completeness: Are all expected records present?
- Volume Trends: Are incoming data volumes normal, or did something break upstream?
- Schema Changes: Did someone alter the structure without notifying the model team?
Modern systems go a step further — implementing feedback loops between AI and data infrastructure.
If model confidence drops or outputs drift, the AI system can automatically request pipeline re-evaluation, data cleansing, or model retraining — creating a self-healing ecosystem.
6. Business Example: The Netflix Personalization Engine
Netflix’s personalization engine exemplifies real-time data delivery at global scale.
- Every viewing session generates dozens of events per second — content pauses, rewinds, likes, and skips.
- These events flow through Kafka-based pipelines into BigQuery and Spark ML models that predict what users are likely to watch next.
- Within seconds, the recommendation interface refreshes — serving tailored thumbnails, genres, and autoplay previews.
This constant feedback between user behavior → data pipeline → AI inference → interface response is what makes the experience seamless and hyper-personalized.
Result:
Over 80% of content streamed on Netflix comes from algorithmic recommendations — a direct product of Big Data and AI working in real time.
7. Why “Right-Time Data” Is the New Competitive Edge
Enterprises are now shifting from “real-time” to “right-time” data — the philosophy that not all data needs to be instant, but all must be timely for its purpose.
- Fraud detection → microseconds matter
- Marketing attribution → hourly updates suffice
- Strategic analytics → daily batches are ideal
Big Data infrastructures provide this flexibility, ensuring that each AI workflow operates at its optimal temporal cadence — balancing cost, freshness, and performance.
In short, delivering the right data at the right time transforms AI from a static system into a living organism that continuously perceives, learns, and adapts.
8. Summary: From Data Plumbing to Intelligence Plumbing
The journey from raw data to AI insight is not a single pipeline — it’s a network of interconnected systems designed for speed, accuracy, and context.
Big Data’s role is to orchestrate that network, ensuring every dataset that reaches an AI model is:
- Fresh and relevant
- Ethically sourced and compliant
- Feature-ready and consistent
- Measurable, observable, and improvable
When executed properly, enterprises move beyond simple analytics and into the realm of continuous intelligence — where data doesn’t just inform decisions but drives them autonomously.
Data Agility and Flexibility
One of Big Data’s greatest contributions to AI is data agility — the ability to test hypotheses, iterate on datasets, and explore new features without infrastructure constraints.
From Sampling to Exhaustive Analysis
Historically, data scientists relied on small, curated datasets due to compute limits. Today, Big Data architectures enable full-scale analysis across millions of variables, delivering granular insights once considered infeasible.
With platforms like Databricks, Snowflake, or Google Vertex AI Workbench, teams can spin up analytical sandboxes — isolated, high-powered environments where models are trained, validated, and tested without affecting production systems.
As AI pipelines and Big Data systems grow in complexity, modular software design becomes critical. Developers often use principles like Dependency Injection to decouple components — for example, separating data ingestion logic from machine learning modules or storage adapters.
Breaking Down the 4 Vs
- Volume: Petabyte-scale datasets can be queried interactively using distributed systems.
- Velocity: Streaming analytics supports real-time decision-making (e.g., detecting anomalies as they happen).
- Variety: Multi-modal datasets (text, image, sensor) can be merged for holistic models.
- Veracity: Data quality pipelines continuously validate accuracy and remove noise.
This agility lets AI systems continuously evolve — retraining models with new data, improving accuracy, and keeping pace with changing user behaviors.
Scalability and Future Readiness
Scalability is where Big Data truly transforms AI from a laboratory concept into a production powerhouse.
Elastic Infrastructure
Modern Big Data ecosystems use containerization and orchestration (via Kubernetes, Docker, and Ray) to scale AI workloads automatically. Enterprises can run distributed training across thousands of nodes — training models faster while managing cost.
This elasticity also supports multi-tenant AI systems, where each business unit or customer can access personalized insights without resource contention.
Adaptive AI Systems
Scalability isn’t just about infrastructure — it’s also about adaptability.
When new data sources emerge (for example, new customer touchpoints, IoT devices, or external APIs), Big Data infrastructure can onboard them seamlessly. AI models are retrained or fine-tuned incrementally, maintaining model freshness without full retraining cycles.
Example: Predictive Manufacturing
A global manufacturer can collect real-time machine sensor data, combine it with maintenance logs, and feed it into an AI model that predicts equipment failures.
Big Data provides the continuous stream; AI provides the predictive intelligence. Together, they reduce downtime, improve safety, and save millions annually.
Industry Case Study: MetLife’s Data-Driven Transformation
The insurance industry generates vast amounts of complex data — policy applications, medical records, claims, and customer interactions. Historically, this data remained siloed and unstructured, limiting operational intelligence.
MetLife, one of the largest insurers globally, tackled this challenge by integrating Big Data and AI into its enterprise architecture.
MetLife’s Big Data–AI Strategy
- Speech Recognition and NLP:
- Voice analytics transcribe and analyze customer service calls to detect sentiment, compliance issues, and emerging claim patterns.
- Machine Learning for Claims Optimization:
- AI models process handwritten documents and medical forms, drastically reducing manual claim review time and error rates.
- Predictive Underwriting:
- Using telematics data (driving behavior, health data from wearables), AI generates real-time risk profiles. Underwriting becomes faster, more precise, and data-driven.
The outcome?
MetLife increased operational efficiency, improved customer satisfaction, and developed a competitive advantage through data intelligence. It transformed unstructured data into a predictive engine for long-term customer engagement and profitability.
The Road Ahead: The Symbiosis of AI and Big Data
AI and Big Data are interdependent technologies.
Big Data is the fuel — the raw material for insights.
AI is the engine — converting that raw input into actionable intelligence.
As enterprises continue their digital evolution, this symbiosis will define the next wave of innovation:
- Hyper-personalization: Real-time adaptation of content, pricing, and recommendations based on user behavior.
- Autonomous Decision-Making: AI agents managing logistics, finance, and operations without human intervention.
- Ethical AI: Big Data governance ensuring fairness, bias detection, and compliance with data protection laws.
- Edge AI: Distributed intelligence moving closer to data sources — enabling low-latency predictions in IoT devices and vehicles.
Organizations that master this convergence won’t just react to data — they will anticipate it, predicting what customers want, how systems will behave, and where opportunities will emerge next.
✉️ Get free faang interview cheat sheet and interview tips weekly
✉️ Get free faang interview cheat sheet and interview tips weekly


