
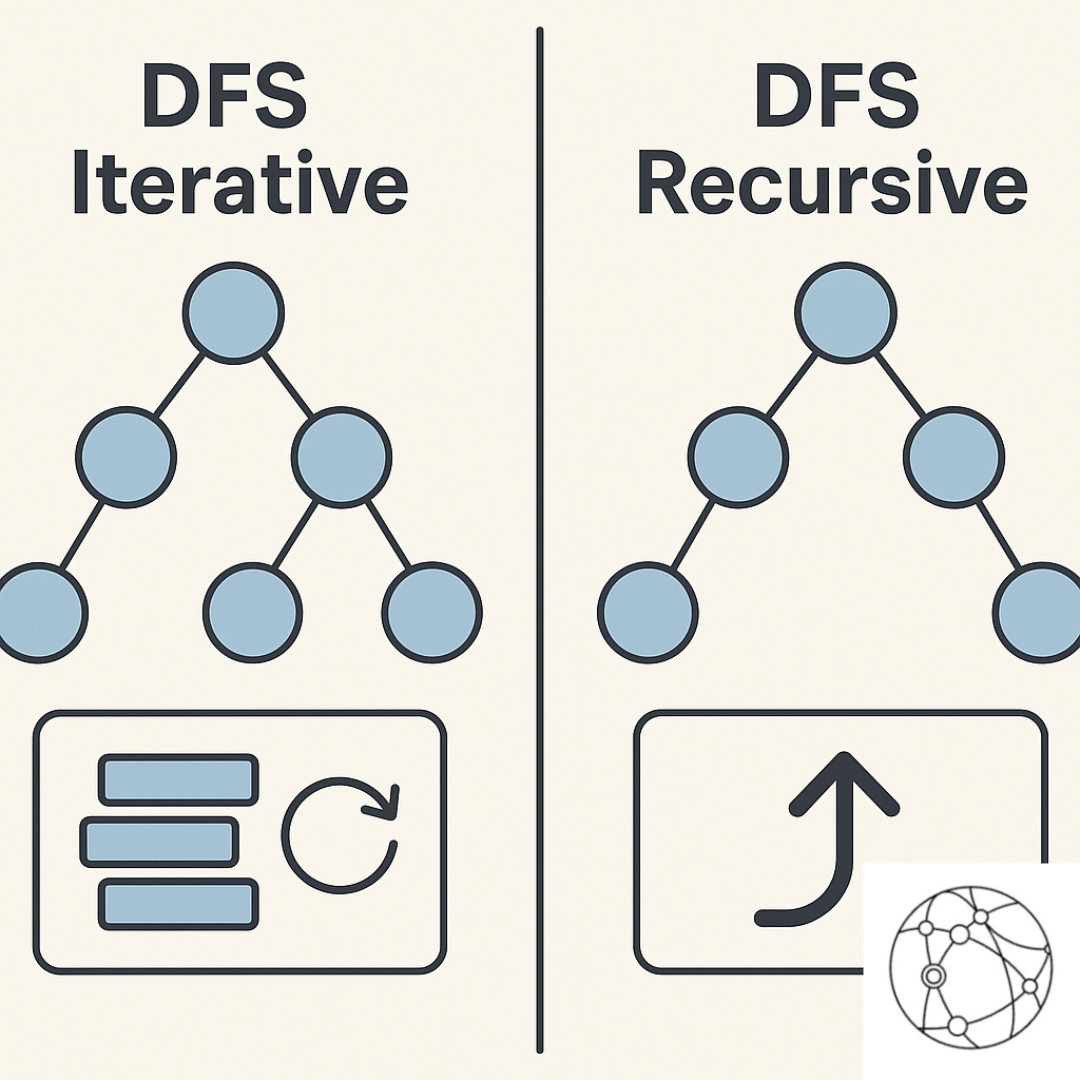
DFS Iterative vs Recursive: When to Use Each and Why It Matters
DFS Iterative vs Recursive: When to Use Each and Why It Matters
Think choosing between recursive and iterative DFS is just a matter of style? Not if you care about stack overflows, interview performance, or debugging production code.
Understanding both DFS approaches isn’t just about passing a whiteboard round. It’s about knowing which tool to pull out when memory matters, when the input graph might be too deep, or when you’re trying to impress your future team by writing code that doesn’t implode on large input sizes.
This is your go-to guide to DFS recursive vs iterative—what each means, when to use them, and how to talk about them like a seasoned engineer.
Depth First Search: The Basics
Before we break it down into recursive vs iterative, let’s make sure we’re on the same page about DFS itself.
Depth First Search (DFS) is a graph traversal algorithm that starts at a source node and explores as far as possible along each branch before backtracking. It’s used in everything from puzzle-solving to detecting cycles to topological sorting.
You can implement DFS either:
- Recursively, letting the call stack handle traversal.
- Iteratively, using your own stack data structure.
Same algorithm. Different trade-offs. And those differences matter more than most developers think.
DFS Recursive
What It Means
Recursive DFS relies on function calls to keep track of traversal. Every time you explore a node’s neighbor, you make a recursive call, and the call stack keeps track of where you’ve been.
def dfs_recursive(node, visited):
if node in visited:
return
visited.add(node)
for neighbor in graph[node]:
dfs_recursive(neighbor, visited)
It’s elegant, readable, and often the default teaching method.
When to Use It
Use recursive DFS when:
- You’re dealing with a small-to-medium graph (less than 10^4 nodes is generally safe).
- You want maximum readability and clarity.
- You don’t expect deep recursion (e.g., the graph isn't a long chain).
Pros and Cons
Pros
- Concise and easy to write
- Mirrors the logical structure of DFS
- Great for interviews when code brevity matters
Cons
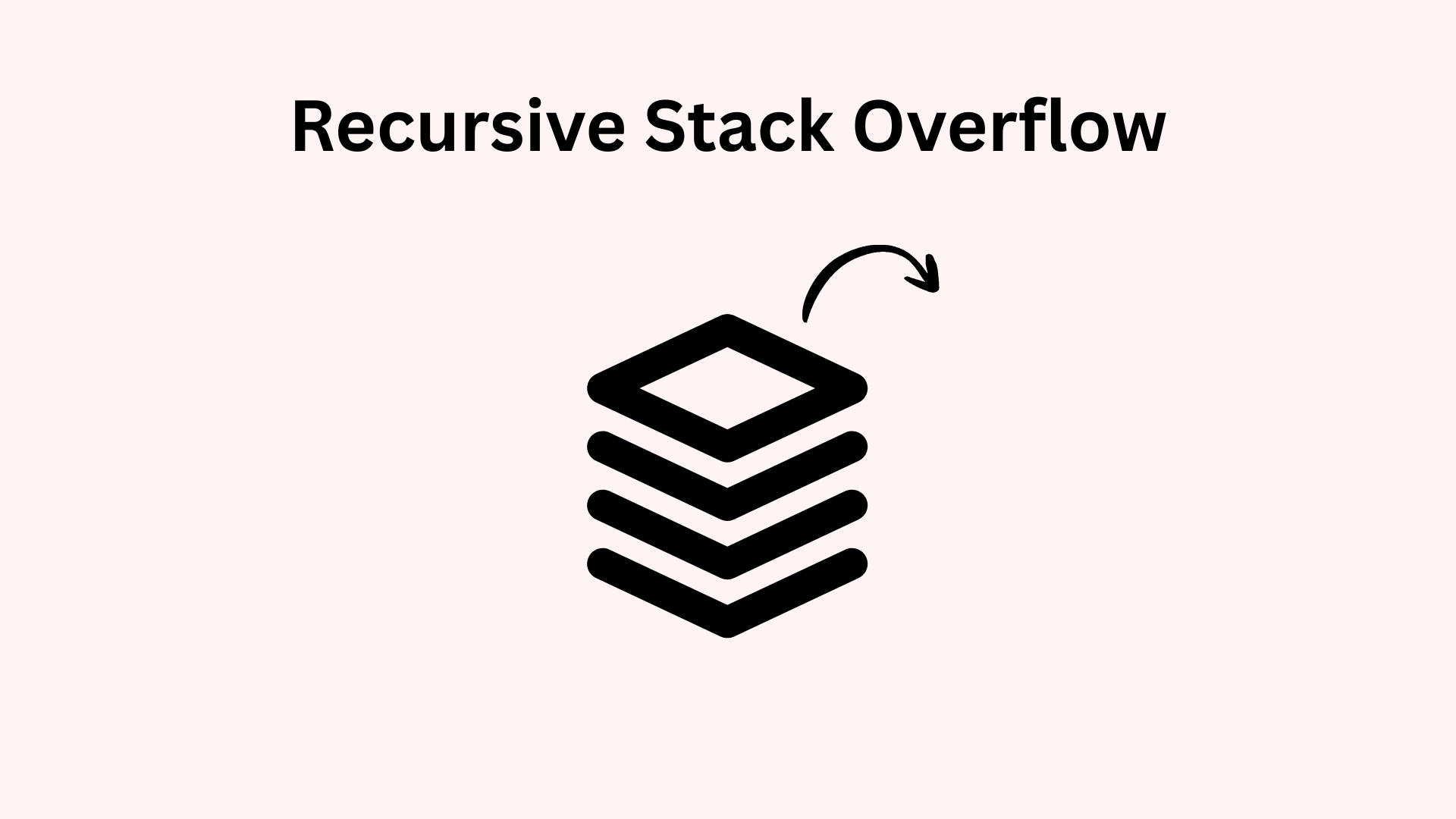
- Can cause stack overflow on deep graphs
- Harder to debug if you lose track of the call chain
- Can be slower due to overhead from recursive calls
DFS Iterative
What It Means
Iterative DFS replaces the call stack with your own stack data structure. It’s a bit more boilerplate—but you get more control over how memory is used and can handle much deeper traversals.
def dfs_iterative(start_node):
visited = set()
stack = [start_node]
while stack:
node = stack.pop()
if node not in visited:
visited.add(node)
for neighbor in reversed(graph[node]):
stack.append(neighbor)
Note the reversed order: it preserves the same traversal order as the recursive version.
When to Use It
Use iterative DFS when:
- You're working with very deep graphs that might exceed recursion limits.
- You need precise control over stack behavior.
- You’re writing production code that needs to be robust against unexpected input sizes.
Pros and Cons
Pros
- No risk of stack overflow
- More memory-safe for large or deep graphs
- Easier to customize behavior during traversal
Cons
- More verbose and harder to read
- Less intuitive if you're new to stack-based logic
- Easy to make off-by-one or order-of-operations mistakes
When to Choose DFS Iterative vs Recursive
Here’s how to think about it in practice:
If you don’t know how deep your input could be, default to iterative. Production environments don’t throw runtime errors because of elegance—they break when the call stack runs out of space.
Real-World Application for DFS
DFS isn’t just a toy problem. It powers:
- Web crawlers: exploring a site’s structure
- Maze solvers: pathfinding through unknown terrain
- Version control (e.g., Git): walking through commit graphs
- Cycle detection: validating graphs in data pipelines
- Deadlock detection: in operating systems or database systems
In all of these, the choice between iterative and recursive could be the difference between "works locally" and "crashes in prod with 10K+ nodes."
How It Shows Up in Interviews
You’ll often get DFS questions in coding interviews—but how you implement it can shape the entire conversation.
For IC Engineering Roles:
- Interviewers want correctness and clean code first.
- Recursive DFS is totally fine—as long as you know the limitations.
- Bonus points if you mention what happens when the recursion depth exceeds Python’s limit (~1000 by default).
For Engineering Lead or EM Roles:
- Expect meta-questions: “How would you handle this in production?”
- You may be asked: “Would this scale to 10M nodes?”
- You should bring up memory use, stack overflow risks, and failure modes—even if you write the recursive version first.
Pro tip: Mention that recursive DFS is easier for devs to grok quickly, but iterative is safer for unknown depths in prod. Framing this trade-off well makes you sound like someone who’s had to debug real outages—not just pass algorithm rounds.
Conclusion
Recursive DFS is clean, quick, and great for learning. Iterative DFS is robust, scalable, and production-ready.
The real skill isn’t just knowing how to implement DFS—it’s knowing when to use each version.
Interviews may only care about correctness, but your code in production should care about stack depth, readability, and crash resilience. Choose the version that fits the job—not just the test case.
And remember: writing both versions shows mastery. Explaining when and why to use each shows leadership.
✉️ Get free faang interview cheat sheet and interview tips weekly
✉️ Get free faang interview cheat sheet and interview tips weekly


